Le machine learning décrypté – 3/3 : Types d’apprentissage et limites
Faire appel au machine learning consiste premièrement à réaliser un programme capable d’apprendre à partir d’un jeu de données. Cet apprentissage peut suivre plusieurs modes, en fonction des exemples exploités. Nous allons faire un focus sur les deux principaux : supervisé et non supervisé. Avant de conclure cette série d’articles par quelques limites intrinsèques au machine learning.
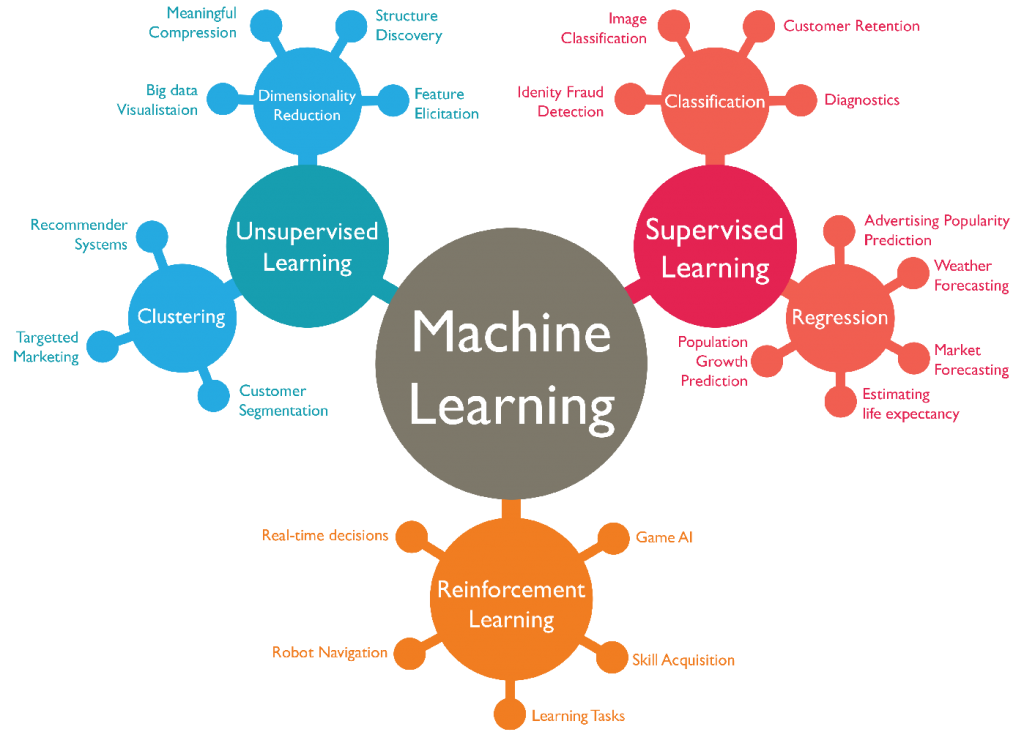
Apprentissage supervisé
On parle d’apprentissage supervisé lorsque les données à l’entrée sont « étiquetées ». C’est-à-dire que chacune d’entre elles est reliée à une classe ou un nom. Par exemple, une série de photos pourra comprendre à chaque fois un titre correspondant à l’élément principal (visage, chat, ballon…). Par conséquent, ce modèle nécessite une mise en forme préalable des données d’entraînement.
Ce procédé est particulièrement utilisé pour reconnaître ou classer des éléments. Dans ce cas, le programme commence par apprendre à partir des données labellisées et par déduire un modèle commun. Par exemple, on peut lui fournir une série de caractères manuscrits, incluant à chaque fois la lettre représentée. Avec un jeu de données suffisamment complet, l’algorithme sera ensuite capable d’analyser de nouvelles images et d’identifier chaque lettre écrite. On obtient alors un système de reconnaissance de texte manuscrit.
Apprentissage non supervisé
Au contraire, dans l’apprentissage non supervisé, le programme est un peu plus livré à lui-même. Il doit en effet toujours apprendre d’une grande quantité de données, mais cette fois, elles ne possèdent aucune étiquette.
Ainsi, l’algorithme de machine learning est lui-même responsable de trouver des caractéristiques communes au sein des données d’entraînement. À partir de ses « observations », il se crée en quelque sorte sa propre représentation du monde (tout du moins des bribes qu’on lui en présente), avec des règles qu’il appliquera sur de nouveaux éléments.
L’apprentissage non supervisé peut servir à effectuer des regroupements à partir d’une collection d’images. Ainsi, le programme pourra par exemple rassembler toutes les photos représentant un chat. Pour cela, il aura préalablement repéré les caractéristiques majeures de l’animal. Il ne saura pas qu’il porte le nom de « chat », mais il identifiera des traits communs : pattes, oreilles, moustaches… Qu’il pourra ensuite reconnaître sur de nouvelles images, pour les regrouper selon ces critères.
Big data and machine learning for Businesses,
by Abdul Wahid
Les limites du machine learning
Le machine learning représente donc un outil puissant, dans la mesure où il peut créer ses propres modèles à partir de données, même non qualifiées. Mais cet atout peut également constituer une faiblesse.
En effet, pour être pertinent, ce procédé requiert une grande quantité de données. Qui sont de plus en plus disponibles, notamment avec le big data. Mais augmenter leur volume implique un plus grand besoin en ressources matérielles, pour leur traitement. Ce qui peut rapidement faire croître le temps nécessaire à l’apprentissage. Par exemple, en avril 2019, une machine a réussi à battre des champions de Dota 2. Mais il lui a fallu 10 mois d’apprentissage pour maîtriser ce jeu vidéo, et dans une version simplifiée !
Avril 2019, une machine a réussi à battre des champions de Dota 2
Par ailleurs, la dépendance du machine learning aux données d’entrée entraîne un autre problème. Car si les exemples fournis sont biaisés, cette partialité sera ensuite reproduite par le programme. Ainsi, en 2014, Amazon a commencé à utiliser un algorithme dédié à la présélection automatique de CV pour son recrutement. Mais l’entreprise a finalement mis un terme à cette expérience, s’apercevant que son outil procédait à une discrimination sexiste pour les postes de développeur ! Et pour cause : les profils, servant de données d’entraînement de l’algorithme, étaient majoritairement masculins dans ce métier…
Aussi automatique soit-il, le machine learning demeure donc un système dépendant de son concepteur. Et s’il est capable de simuler, d’une certaine façon, la capacité d’apprentissage de l’être humain, il peut également amplifier ses travers.