Introduction au NLP - Partie 4/6 - Traitement sémantique & traitement pragmatique
Nous avons présenté, dans la Troisième partie, les analyses phonologique et morpho-syntaxique permettant de passer de la série de sons à la séquence de syntagmes logiquement articulés à l’échelle de la phrase.
En reprenant la dynamique du NLP, faisons un saut qualitatif. Il s’agit d’établir à présent de quelle manière la séquence est interprétée par la machine, en tenant compte des informations contextuelles.
En quoi les analyses sémantique et pragmatique consistent-elles ? Quels méthodes et outils applique-t-on ? Voici quelques explications pour comprendre, des signes au sens, comment la “magie” opère.
Troisième niveau. Traitement sémantique
S’il est une tâche complexe, c’est bien l’analyse sémantique du langage. Et pour cause : elle exige de trouver la relation adéquate entre les signes et l’ensemble des concepts et des représentations possibles. Pour cette raison, de nombreux modèles et approches existent.
On distingue, à ce niveau, la sémantique lexicale à l’échelle des mots, et la sémantique propositionnelle, à l’échelle de la phrase.
Sémantique lexicale
Commençons par la sémantique lexicale. De quelle façon la machine peut-elle découvrir le sens d’un mot ou d’un syntagme ?

Source : Unsplash
● Les réseaux de concepts
Les réseaux de concepts sont très utiles dans la mesure où ils mettent en rapport des mots avec d’autres afin d’en déterminer le sens.
On identifie pour commencer les hyponymes et les hypéronymes. Par exemple, les noms fauteuil, chaise, canapé sont des hyponymes de l’hyperonyme siège. Les algorithmes identifient également des synonymes et des antonymes.
Représentés sous formes de graphes, avec des noeuds et des arcs, les réseaux de concepts sont des modèles décrivant le lexique. Ils rendent compte des concepts associés à chaque mot ainsi que des aspects relationnels existants dans le réseau (objet, moyen, agent).
● Les vecteurs de mots
Une autre approche est celle des vecteurs de mots. À chaque mot, ainsi, correspond un certain nombre de propriétés définitoires (ou variables), en général entre 25 et 300. Les vecteurs de mots sont utilisés en machine learning et en deep learning, avec au début des itérations l’attribution de variables aléatoires.

Source : Université de Strasbourg
Sémantique propositionnelle
À partir du sens de chaque mot et de ses relations avec son entourage, il s’agit de révéler le sens de la phrase. Dans ce but, le NLP s’appuie sur l’analyse lexicale et sur les rôles syntaxiques. Dans cette délicate opération de la construction du sens, plusieurs distinctions interviennent.

Source : Unsplash
● L’instanciation
L’instanciation permet de repérer en premier lieu des catégories sémantiques.
Par exemple, l’utilisation du déterminant permet de construire un exemplaire d’une classe. Dans la phrase “Le chatbot Clevy est désormais utilisé par la ville d’Orléans”, le sujet de la phrase est un exemplaire de classe (on parle d’un chatbot particulier, nommé Clevy). La valeur en revanche est générique dans l’énoncé : “Les études montrent qu’un chatbot est efficient pour la plupart des sociétés” (soit l’utilisation d’un chatbot quel qu’il soit).
Un des aspects importants de l’instanciation est de vérifier si un élément nouveau est introduit ou s’il s’agit de la reprise d’un élément déjà mentionné. Dans la phrase “Clevy est utilisé par plusieurs services en entreprise. Il est efficace à 90%”, on retiendra le deuxième cas pour identifier l’antécédent du pronom “il” (“Clevy” est l’antécédent ; il ne s’agit pas d’une nouvelle personne, objet ou entité).
● Les relations
L’étude des relations permet de distinguer les rôles des acteurs de la phrase, en répondant à des questions simples (“Qui a fait quoi ? à qui ? avec quoi ?”). Le but est de construire des événements, des entités, des arguments, etc. On parle de principe de compositionnalité, suivant la théorie du linguiste et logicien Gottlob Frege, au début du XXe siècle.
« Le sens d’une expression, écrit un commentateur de Frege, ne dépend que du sens de ses composants et des règles syntaxiques par lesquelles ils sont combinés ». C’est en vertu de ce principe qu’il est possible de comprendre une phrase que l’on n’a jamais entendue auparavant (pour un humain) ou qui ne figure pas dans tel corpus de référence (pour la machine).
Avec le traitement sémantique et l’apprentissage automatique, un sens est ainsi dégagé pour les mots puis la phrase. Ce sens reste toutefois littéral, délié à la fois de la situation réelle et de notre représentation du monde.
Quatrième niveau. Traitement pragmatique
Le quatrième niveau du NLP, celui de l’analyse pragmatique, permet un ancrage du sens. C’est à ce niveau que sont traités le contexte, la situation d’énonciation et l’univers de référence du locuteur. Nous allons évoquer ces points et les réponses apportées en NLP.

Source : Burst
● Ego, hic, nunc, la contrainte de l’indexicalité
Le sens de certains énoncés n’est pas totalement compréhensible avec le seul outil logique. La phrase “Est-ce que quelqu’un aurait un stylo ?” est en fait une demande, par exemple. La signification du pronom “je” ou de l’adverbe déictique “ici” dépend de la situation d’énonciation et du contexte. On parle dans ce cas d’indexicalité.
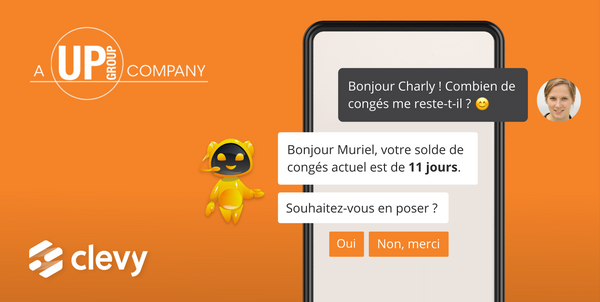
Si un salarié pose à Clevy la question “Combien me reste-t-il de jours de congés ?”, il revient au chatbot de demander à l’interlocuteur son nom – ou de le rechercher, ou de l’avoir identifié au préalable – pour accéder à la requête. En NLP, il faut souvent recourir à des algorithmes de filtrage et d’explication pour dissiper les mystères, quelquefois denses, de l’indexicalité.
● Situation et univers de référence
Les inférences renvoient aux éléments propres à la situation de communication, à l’univers de connaissances du locuteur et du groupe humain auquel il appartient. Ces éléments, dans la mesure où ils relèvent souvent de l’implicite, représentent des obstacles importants en NLP.
Source : Unsplash
L’inférence est le fait de déduire, d’induire, d’interpréter, à partir de ce qui est dit ou montré. Par exemple, si un collaborateur dit “Je vais retrouver ma famille en décembre”, on peut supposer qu’il évoque la période de ses congés à Noël.
Dans le cas d’un chatbot, l’entraînement permettra de préciser les situations et les références pertinentes, en rapport avec les utilisateurs et le cadre d’utilisation de l’outil. Il s’agira, par exemple, d’apprendre au chatbot le vocabulaire de l’entreprise dans laquelle il sera utilisé. Avec le machine learning, le chatbot pourra se perfectionner de façon autonome.
En NLP, des moteurs d’inférences peuvent être utilisés. Ils permettent de trouver et de tester des hypothèses de déduction logiques, avec un filtrage statistique. Pour confirmer la pertinence de ces déductions, il faudra le plus souvent recourir à un validateur humain.
Refermons ce quatrième volet. Le traitement sémantique permet donc d’établir le sens littéral des énoncés. Le traitement pragmatique, ensuite, de l’ajuster à la situation réelle de communication et à l’univers du locuteur. Si dans chaque étape les performances de la machine – du son au sens – ont de quoi fasciner, les limitations restent nombreuses.
Dans la Cinquième partie, nous allons donc recenser les obstacles qui se présentent encore aux chercheurs et aux ingénieurs en NLP.