Introduction au NLP - Partie 3/6 - Traitement phonologique & morpho-syntaxique
Dans la Deuxième partie, nous avons résumé les progrès du NLP et précisé ses usages actuels – de l’assistant virtuel au chatbot.
Intéressons-nous maintenant, concrètement, au fonctionnement du NLP. Par quelles étapes passe-t-on pour traiter une séquence parlée ou écrite ? Comment la linguistique, les probabilités, le machine learning sont-ils mobilisés ?
Voici de quoi comprendre les opérations principales intervenant dans le NLP, sans oublier les algorithmes les plus utilisés.
Plusieurs niveaux d’analyse
La mise en œuvre du NLP représente un colossal travail de classification, comparaison, modélisation – effectué instantanément par la machine grâce à sa puissance de calcul.
Deux grandes approches existent. D’un côté, une approche statistique, dépendantes des grands corpus, privilégiant les n-grammes et le machine learning. De l’autre, une approche linguistique, supposant un travail de conceptualisation plus complexe.
On distingue ensuite quatre niveaux d’analyse du langage, avec un degré d’abstraction croissant.
Premier niveau. Traitement phonologique
Commençons par quelques observations.
Clavier et écran sont en train de subir un déclassement technologique. Plus intuitive, immédiate, ne nécessitant pas d’acculturation technologique, la voix serait en passe de devenir la nouvelle interface naturelle. D’après une étude d’Accenture, d’ici à 2024, au moins 50% des interfaces seront vocales.
Alors, que se passe-t-il lorsque vous interrogez votre assistant personnel virtuel – une pratique qui risque de se généraliser rapidement ?

Source : Unsplash
● Acoustique, phonétique, phonologie
En premier lieu, un traitement acoustique intervient. Ensuite, les sons (phonèmes) sont analysés les uns après les autres. Cette étude relève de la phonologie. La prosodie analyse l’accentuation, le rythme, l’intonation : elle permet de confirmer la présence d’espaces typographiques et de signes de ponctuation. On repère également les modalités déclarative, exclamative, injonctive, ou interrogative, de la phrase.
En outre, à votre intonation, on peut déceler votre humeur – impatience, surprise, colère, joie, etc. Un potentiel intéressant pour le NLP.
● L’algorithme n-gramme
Pour le traitement phonologique et lexical, l’algorithme n-gramme est utilisé. Ce modèle calcule à travers un apprentissage automatique la probabilité selon laquelle des éléments se présentent. Un étiquetage, en interrogeant une vaste base de données, permet d’identifier la série la plus probable.
● Transcription
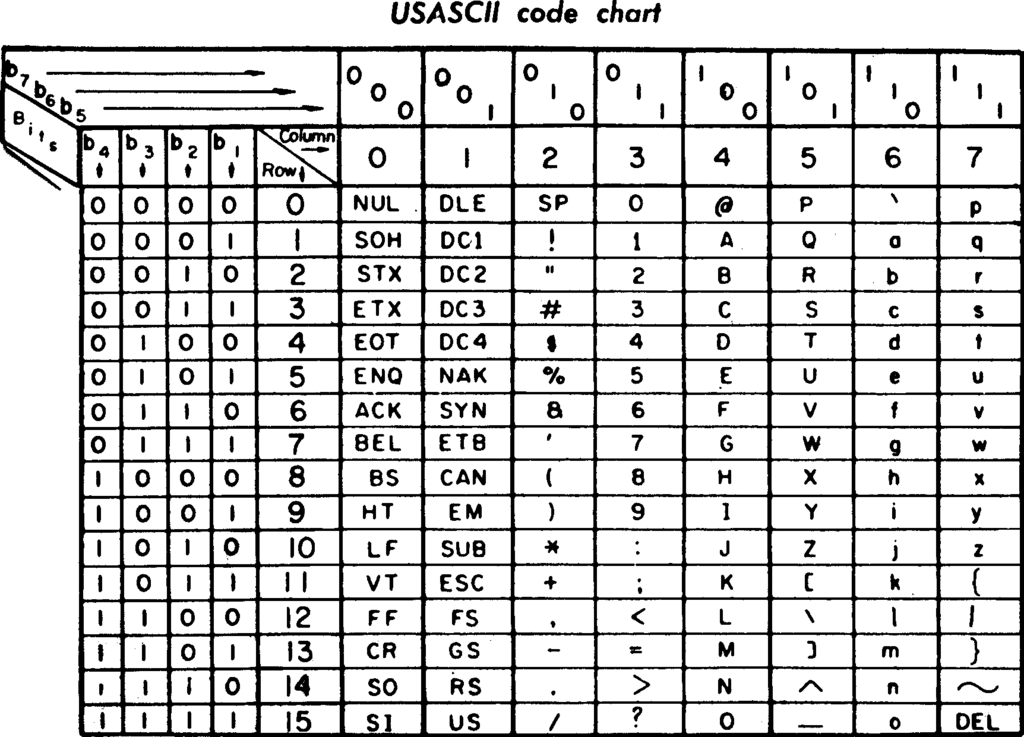
La séquence orale est après transcrite. Cette opération est possible grâce à l’encodage, la correspondance entre le langage binaire et les lettres et chiffres. On utilise, selon les cas, le code ASCII (American Standard Code for Information Interchange), l’Unicode, L’IPA (International Phonetic Alphabet).
À travers ce premier niveau, il est donc possible de cheminer des sons à la séquence de mots.
Comment par la suite procède-t-on pour identifier les caractéristiques des mots et les relations qu’ils entretiennent ?
Deuxième niveau. Traitement morpho-syntaxique
Le deuxième niveau relève de la morpho-syntaxe. Il s’agit de progresser dans l’analyse : en passant de la structure du mot à celle du groupe de mots (syntagme) et à l’organisation des composants de la phrase.
La morphologie correspond à la structure interne des mots, des éléments appelés morphèmes. L’approche syntaxique permet d’appréhender de façon logique le schéma de la phrase et ses possibilités.

Source : Unsplash
● Tokenization et loi de Zipf
Dans le cas d’une requête écrite, la première étape est la segmentation. Les séparateurs – espaces ou signes de ponctuation – délimitent les mots. La tokenization permet également de distinguer les phrases.
La loi de Zipf, démontrant que plus un terme est fréquent, moins il est pertinent (déterminants, conjonctions, prépositions, etc.), permet de concentrer le travail préliminaire sur les éléments porteurs de sens.
● Lexique & grammaire
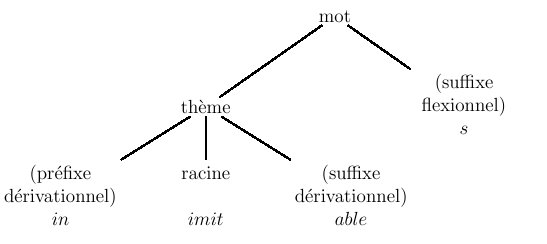
Concrètement, les morphèmes peuvent désigner les préfixes, les terminaisons verbales, etc. Il y a ainsi deux catégories de morphèmes.
La première comprend les morphèmes lexicaux, qui représentent une classe libre, celle des noms, verbes, adjectifs, adverbes. La seconde famille regroupe les morphèmes grammaticaux. Il s’agit d’une liste de flexions (genre, nombre) et terminaisons verbales. Les affixes, regroupant les préfixes et les suffixes, appartiennent à la seconde catégorie ou sont rangés dans une catégorie à part, celle des morphèmes dépendants.
À partir de ces catégories, plusieurs algorithmes s’appliquent. On parle à ce stade d’annotation du corpus.
● Stemming, lemmatization, regex, TreeTagger
L’algorithme de Porter, ainsi, permet de distinguer la racine d’un mot, en supprimant affixes et désinences. On parle dans ce cas de stemming (racinisation).

La lemmatization, un peu différente, permet de conserver la forme grammaticale correcte du mot, celle du dictionnaire – quand l’algorithme de Porter produit des formes qui ne sont pas canoniques.

Les expressions régulières sont très utiles en NLP. On les utilise au moment de la tokenization pour parcourir (parser) la chaîne de caractères. À un niveau plus avancé, les regex fournissent des résultats correspondant à des modèles (patterns) morpho-syntaxiques particuliers.

Évoquons aussi le TreeTager permettant d’effectuer une tokenization, une lemmatization et un étiquetage.
● Étiquetage de la syntaxe
Des unités de sens dotées de caractéristiques lexicales et grammaticales sont donc identifiées. L’objet de l’analyse syntaxique est de repérer les dépendances entre ces syntagmes (chunks).

Source : Cahiers de l’Herne
Beaucoup d’algorithmes de NLP s’appuient sur les travaux de Noam Chomsky, célèbre linguiste américain, dont les théories s’échafaudent autour de l’importance de la syntaxe.
Chercheurs et ingénieurs recourent à des apprentissages supervisés, en interrogeant des bases de données. Ils instituent des règles de probabilités, souvent avec des graphes. Les réseaux de transition récursifs sont particulièrement efficaces. Il s’agit d’automates d’intelligence artificielle, modélisant tous les états possibles des phrases.
● Exemple
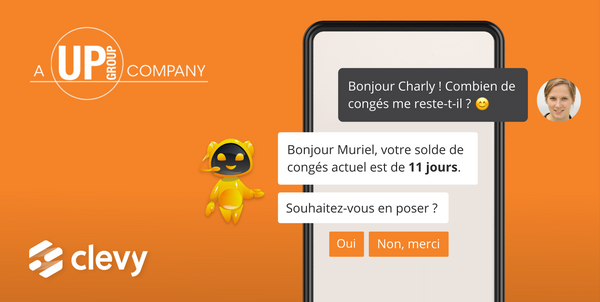
Si vous demandez au chatbot Clevy : “Comment poser mes congés ?”, le traitement syntaxique permet de distinguer les relations entre différents syntagmes.
Dans cet exemple, “Comment” est un adverbe interrogatif. “Poser mes congés”, un groupe verbal avec un verbe à l’infinitif et son complément d’objet direct, lui même un syntagme nominal composé d’un pronom (“mes”) et d’un nom masculin pluriel (“congés”).

Source : Clevy.io
Au final, à partir d’une question prononcée devant un objet équipé d’un micro, ou tapée dans la fenêtre d’une application, un processus complexe s’organise. Il est fait de calculs, de règles, mobilisant les ressources de la linguistique, de la statistique, du machine learning. En somme, il s’agit de traduire les sons en mots, les mots en morphèmes, les morphèmes en syntagmes, et d’identifier leurs relations.
To be continued. Mais comment évolue-t-on des signes au sens ? Dans la Quatrième partie, nous allons parler sémantique et pragmatique pour comprendre comment la machine interprète le langage naturel.