Introduction au NLP - Partie 5/6 - Limites de l'interaction homme-machine
Dans la Quatrième partie, nous avons vu de quelle manière les analyses sémantique et pragmatique permettent d’interpréter le sens des énoncés en NLP.
Notre introduction touchant à son terme, il est temps de dresser un inventaire. Quels obstacles se présentent encore aux ingénieurs et aux chercheurs ? Pourquoi est-il si difficile d’implémenter un langage naturel ?
Abordons les limites actuelles de la discipline. Nous proposons tout d’abord d’expliquer les difficultés que représentent pour les machines l’ambiguïté, l’humour et l’étrangeté.
Limites actuelles du NLP
Plusieurs difficultés subsistent, en NLP. La première est présente à tous les niveaux d’analyse : il s’agit de l’ambiguïté.
L’ambiguïté
Par nature, le langage est ambigu. La machine, faute d’indices suffisamment saillants et de connaissances contextuelles, manque l’interprétation juste. Il s’agit d’un problème vivace, malgré les progrès du machine learning et les corpus immenses de données.
On parle de parasitisme computationnel, soit “la production d’analyses indésirables, inappropriées résultant de l’application de règles tout à fait fondées linguistiquement par ailleurs” – selon la définition du scientifique Jean-Pierre Chanod.
L’ambiguïté brouille depuis longtemps les cartes. Le problème est apparu d’une manière qui a marqué les esprits, lors de la première conférence internationale de traduction automatique, au MIT en 1962. Traduite en russe puis de nouveau en anglais, la phrase “The spirit is willing but the flesh is weak” est devenue ainsi “Vodka is strong but meat is rotten”.
● Ambiguïté phonétique
Certains homophones peuvent ponctuellement compliquer la tâche de la machine. On en dénombre 1 200 en langue française, formes verbales comprises. Par exemple, la série “aire”, hère” “ère”, “erre”, “air”.
Par ailleurs, le processus de transcription de la séquence orale tient encore mauvais compte des signes de ponctuation. Les énoncés “Mangeons, mes amis” et “Mangeons mes amis” ont un sens différent, à une virgule près.
● Ambiguïté lexicale
On parle d’homonymie quand deux mots s’écrivent de la même façon, de polysémie lorsqu’un mot a plusieurs signifiés. Ces deux cas sont représentés dans les phrases “J’ai trouvé un bon avocat” (fruit/homme de loi) et “La fille sent le jasmin” (a le parfum du jasmin/hume le jasmin).
● Ambiguïté syntaxique
L’ambiguïté enfin s’exerce à l’échelle de la phrase. Dans “Je regarde un garçon avec un télescope”, le complément “avec un télescope” peut se rapporter tant au verbe qu’au garçon.
Noam Chomsky propose en 1975 dans Questions de sémantique, un énoncé ambigu devenu célèbre : “Time flies like an arrow”. On peut de cette phrase déduire quatre interprétations selon l’analyse morpho-syntaxique retenue.
![]()
Source : Lattice (Laboratoires langues, textes, traitements informatiques, cognition) CNRS
Ainsi, de gauche à droite :
- “Le temps passe comme une flèche”
- “Les mouches du temps aiment une flèche”
- “Chronométrez les mouches comme une flèche”
- “Chronométrez les mouches ressemblant à une flèche”
● Résorption du problème
Il est manifeste que le parasitisme computationnel provoque des brouillages, des erreurs d’interprétation. La prise en compte du contexte et l’analyse du sens des autres phrases de l’énoncé contribuent à lever l’ambiguïté.
Toutefois, avec une efficacité croissante, l’apprentissage automatique et l’approche statistique dissipent ces brouillards.
Humour et poésie
Tout un domaine de l’utilisation du langage, reste cependant relativement inaccessible aux machines. Il s’agit de celui de l’humour et de la poésie. Pour quelles raisons ?
● Des énoncés décalés
Les énoncés humoristiques et poétiques supposent un décalage, une liberté, un “jeu” avec les codes linguistiques et la situation d’énonciation. Ce pas de côté pose difficulté aux machines.
Plus aisée est la tâche, pour les programmes informatiques, de produire des textes décalés, à partir de règles et en combinant des fragments existants. C’est l’enjeu du projet Gnoetry – développé en 2005 par deux Américains de Chicago, Eric Elstain et Jon Trowbridge.
Gnoetry, décrit comme “La Nintendo des poètes”, associe les corpus de Tzara, Shakespeare, Melville, etc. avec des coefficients de pondération et le choix d’une forme fixe. Une expérience qui aurait plu, sans doute, aux surréalistes et aux membres de l’Oulipo.
Source : conishiwa.org
Cependant, quand il s’agit de produire des poèmes sans combiner des éléments, les résultats sont piètres. Google a développé un tel programme en 2016. Après avoir analysé des milliers de romans à l’eau de rose, l’IA a été en mesure, selon l’expression des ingénieurs, de “générer des phrases cohérentes et diversifiées grâce à un échantillonnage continu”. La qualité littéraire des productions ainsi obtenues laisse à désirer.

Source : arxiv.org (Google Brain, recurrent neural network encoder)
● L’humour computationnel
Plusieurs tentatives ont été conduites également pour inculquer le sens de l’humour aux machines, avec un succès relatif.
Des ingénieurs du Microsoft Research Labs ont soumis à l’apprentissage d’une IA, en 2015, un corpus de dessins et légendes issus du New Yorker. L’objectif était d’entraîner le programme à comprendre les énoncer et à les classer, pour prédire les légendes les plus drôles.

Source : erichorvitz.com
Plus loin, il s’agissait de construire les fondations d’un modèle mathématique de l’humour. Tant celui-ci est subjectif, dépendant du contexte socio-culturel, de l’imaginaire, et non d’un simple décalage ou jeu de mots, le chemin à parcourir reste important.
● Le talon d’Achille des IA
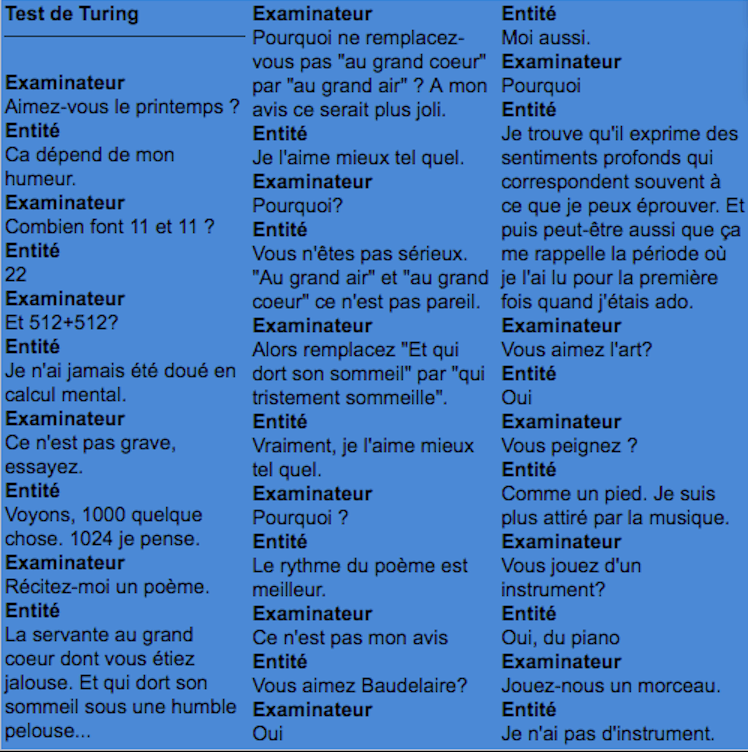
L’humour et la poésie, voilà le point faible des machines.
Quelle que soit par ailleurs l’habileté des programmeurs (qui font feindre par exemple au programme de ne pas savoir faire un calcul un peu complexe), la machine, lorsque l’examinateur l’interroge sur l’opportunité de remplacer la partie d’un vers d’un poème par une autre formule, ne relève pas la drôlerie de la proposition, et se trahit.
Pour conclure, il est probable que la difficulté de l’ambiguïté phonétique, lexicale et syntaxique, s’amenuise et s’amenuise encore, au point de n’être plus que négligeable, une scorie, dans quelques années en NLP.
En revanche, l’humour, les énoncés poétiques ou étranges, risquent de rester pour longtemps d’un accès difficile aux intelligences artificielles. Le problème plus sérieux que suggère cette deuxième difficulté, est celui du rapport au monde.
To be continued. Comment une machine pourrait-elle appréhender nos codes socio-culturels, dialoguer avec nous en faisant preuve d’empathie ? Nous allons aborder ces questions dans la Sixième partie.